学习记录--测试方法基础
边界值分析法
边界是指对于输入等价类和输出等价类而言,稍高于其边界值及稍低于其边界值的一些特定情况。
边界值分析法也是一种常用的黑盒测试方法。
分析边界的原因:大量的错误是发生在输入或输出范围的边界上,而不是在输入范围的内部。
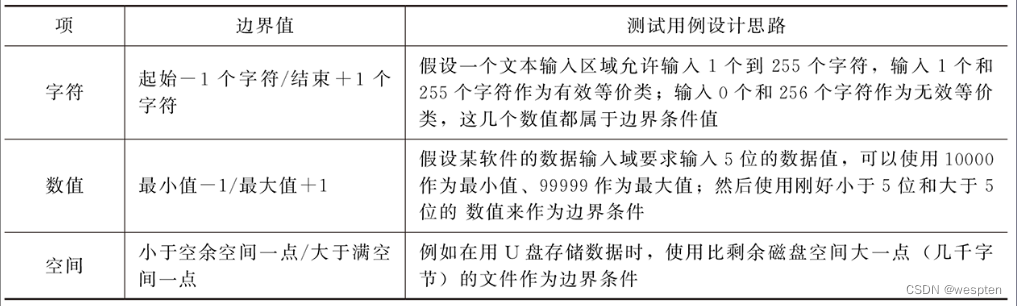
标准边界值分析
标准边界值分析一般使用 5 个值作为测试用例:
- min:输入变量的最小值;
- min+:稍大于最小值;
- nom:域内任意值,一般为中间值;
- max-:稍小于最大值;
- max:最大值;
在多个变量的情况下,只使其中一个变量设为上述 5 个值,其他所有变量均取正常值来进行测试。对于一个 n 变量的程序,使用标准边界值分析需要设计 4n+1 个测试用例。
如果测试边界没有明确给出,可以人工设置边界。例如在三角形问题中设置边长的下界为 1。上界在默认情况下可以使用最大可表示的数值(例如 MAXINT),或者根据实际需求确定一个数作为上界。
用直观的图来表示标准边界值分析法的取值,如图所示:
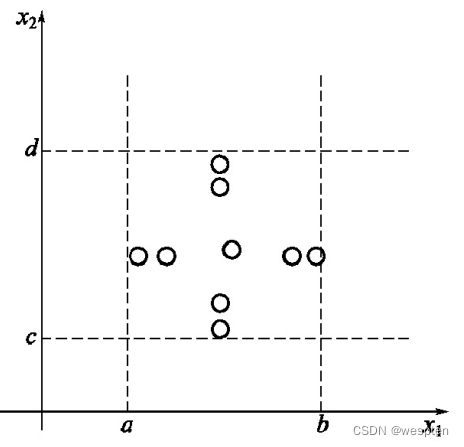
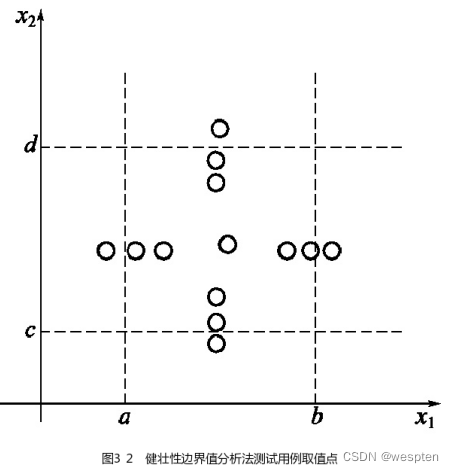
健壮性边界值分析
健壮性是指在异常情况下,软件还能正常运行的能力。健壮性测试是标准边界值分析的一种简单扩展。除了上述的 5 个常见边界值,还要考虑一下两个值:
- max+:略超过最大值;
- min-:略小于最小值;
健壮性测试的最大价值在于观察处理异常情况,它是检测软件系统容错性的重要手段。对于一个n变量的程序,健壮性边界值分析测试会产生 6n+1 个测试用例。边界值分析大部分的测试都可直接用于健壮性测试。健壮性测试最有意义的部分不是输入而是输出,观察边界之外的异常情况如何处理。
用直观的图来表示健壮性边界值分析法的取值,如图所示:
等价类划分法
等价类划分法是一种重要的、常用的黑盒测试方法,它将不能穷举的测试过程进行合理分类,从而保证设计出来的测试用例具有完整性和代表性。等价类划分法是把所有可能的输入数据,即程序的输入划分成若干部分(子集),然后从每一个子集中选取少量具有代表性的数据作为测试用例。采用等价类划分法时,完全不用考虑程序内部结构,设计测试用例的唯一依据是软件需求规格说明书
原因:不可能实现穷举测试,可以从大量的可能数据中选取一部分具有代表性的数据作为测试用例。
效果:经过类别划分后,每一类的代表性数据在测试中的作用都等价于这一类中的其他值。
手段:在设计测试用例时,在需求说明的基础上划分等价类,列出等价表,从而确定测试用例。
等价类划分法设计测试用例要经历2个步骤:划分等价类(列出等价类表);选取测试用例
等价类的划分有2种不同的情况:有效等价类、无效等价类
如何划分等价类
一下节选自《等价类划分》-有这篇就够了 - 知乎 (zhihu.com)
- 如果输入条件规定了一个取值范围(例如,“数量可以是1到999”),那么就应确定出一个有效等价类(1<数量<999),以及两个无效等价类(数量<1,数量>999)。
- 如果输入条件规定了取值的个数(例如,“汽车可登记一至六名车主”),那么就应确定出一个有效等价类和两个无效等价类(没有车主,或车主多于六个)。
- 如果输入条件规定了一个输入值的集合,而且有理由认为程序会对每个值进行不同处理(例如,“交通工具的类型必须是公共汽车、卡车、出租车、火车或摩托车”),那么就应为每个输入值确定一个有效等价类和一个无效等价类(例如,“拖车”)。
- 如果存在输入条件规定了“必须是”的情况,例如“标识符的第一个字符必须是字母”,那么就应确定一个有效等价类(首字符是字母)和一个无效等价类(首字符不是字母)。
- 以上是基于字面上的需求划分的等价类,而细化等价类依据的是数据在内存或数据库中存储的类型。(举例,测试加法器,两个文本框,要求输入-99~99之间的整数。整数的存储在计算机底层中会使用不同的算法,正整数和负整数算法不同。所以测试时正整数和负整数应该分开来测(一般对有效等价类数据应用,无效等价类数据一般不需要正、负分别测)。所以将有效等价类细分为:-99–(-1)负整数、0—99 正整数。
划分等价类应当考虑一下几个方面:
- 完备测试、避免冗余;
- 划分等价类重要的是:集合的划分,划分为互不相交的一组子集,而子集的并是整个集合;
- 并是整个集合:完备性;
- 子集互不相交:保证一种形式的无冗余性;
- 同一类中标识(选择)一个测试用例,同一等价类中,往往处理相同,相同处理映射到”相同的执行路径”。
等价类划分的优缺点
- 优点:等价类划分的测试用例设计方法减少了穷举法带来的大量测试用例,保证测试效果和测试效率,一般是有输入性需求的被测对象可以采用的方法;
- 缺点:输入与输入之间的关系考虑少,可能产生一些逻辑错误。还需要其他用例设计方法来补充测试。
幂等测试
幂等就是一个操作或者接口,不管你调多少次,每次执行的结果都跟第一次一样。
试想这样的一种场景:在电商平台上支付后,因为网络原因导致系统提示你支付失败,于是你又重新付款了一次,等完成后检查网银发现被系统扣了两次款,这显然不对。
使用幂等的场景
1、前端重复提交
用户注册,用户创建商品等操作,前端都会提交一些数据给后台服务,后台需要根据用户提交的数据在数据库中创建记录。如果用户不小心多点了几次,后端收到了好几次提交,这时就会在数据库中重复创建了多条记录。这就是接口没有幂等性带来的 bug。
2、接口超时重试
对于给第三方调用的接口,有可能会因为网络原因而调用失败,这时,一般在设计的时候会对接口调用加上失败重试的机制。如果第一次调用已经执行了一半时,发生了网络异常。这时再次调用时就会因为脏数据的存在而出现调用异常。
3、消息重复消费
在使用消息中间件来处理消息队列,且手动 ack 确认消息被正常消费时。如果消费者突然断开连接,那么已经执行了一半的消息会重新放回队列。当消息被其他消费者重新消费时,如果没有幂等性,就会导致消息重复消费时结果异常,如数据库重复数据,数据库数据冲突,资源重复等。
那么测试的思路如下:
- 第一,从产品的业务逻辑设计和实现上,查看是否做了幂等,比如与时间戳进行幂等
- 第二,遇到支付这些业务的时候,跟多的需要考虑构造支付失败,检查失败之后的处理机制
- 第三,前端测试,通过快速点击,手动的难以实现,可以使用UI自动化手段进行实现
- 第四,后端接口调用。使用jmeter或者postman多次重复发送参数相同的请求,查看服务器返回给我们的response
实现幂等的思路
- MVCC: 多版本并发控制,乐观锁的一种实现,在数据更新时需要去比较持有数据的版本号,版本号不一致的操作无法成功;
- 去重表: 利用数据库表单的特性来实现幂等,常用的一个思路是在表上构建唯一性索引,保证某一类数据一旦执行完毕,后续同样的请求再也无法成功写入。 比如博客上面要想防止一个人重复点赞,可以设计一张表,将博客id与用户id绑定建立唯一索引,每当用户点赞时就往表中写入一条数据,这样重复点赞的数据就无法写入。
- TOKEN机制: 这种机制就比较重要了,适用范围较广,有多种不同的实现方式。其核心思想是为每一次操作生成一个唯一性的凭证,也就是token。一个token在操作的每一个阶段只有一次执行权,一旦执行成功则保存执行结果。对重复的请求,返回同一个结果。以电商平台为例子,电商平台上的订单id就是最适合的token。当用户下单时,会经历多个环节,比如生成订单,减库存,减优惠券等等。每一个环节执行时都先检测一下该订单id是否已经执行过这一步骤,对未执行的请求,执行操作并缓存结果,而对已经执行过的id,则直接返回之前的执行结果,不做任何操作。这样可以在最大程度上避免操作的重复执行问题,缓存起来的执行结果也能用于事务的控制等。
具体的实现流程如下:摘自阿里面试官:接口的幂等性怎么设计? - 知乎 (zhihu.com)
基于Token
- 客户端会先发送一个请求去获取 token,服务端会生成一个全局唯一的 ID 作为 token 保存在 redis 中,同时把这个 ID 返回给客户端
- 客户端第二次调用业务请求的时候必须携带这个 token
- 服务端会校验这个 token,如果校验成功,则执行业务,并删除 redis 中的 token
- 如果校验失败,说明 redis 中已经没有对应的 token,则表示重复操作,直接返回指定的结果给客户端
注意:
- 对 redis 中是否存在 token 以及删除的代码逻辑建议用 Lua 脚本实现,保证原子性
- 全局唯一 ID 可以用百度的 uid-generator、美团的 Leaf 去生成
基于 mysql 实现
- 建立一张去重表,其中某个字段需要建立唯一索引
- 客户端去请求服务端,服务端会将这次请求的一些信息插入这张去重表中
- 因为表中某个字段带有唯一索引,如果插入成功,证明表中没有这次请求的信息,则执行后续的业务逻辑
- 如果插入失败,则代表已经执行过当前请求,直接返回
基于 redis 实现(SETNX )
- 客户端先请求服务端,会拿到一个能代表这次请求业务的唯一字段
- 将该字段以 SETNX 的方式存入 redis 中,并根据业务设置相应的超时时间
- 如果设置成功,证明这是第一次请求,则执行后续的业务逻辑
- 如果设置失败,则代表已经执行过当前请求,直接返回
- 标题: 学习记录--测试方法基础
- 作者: Huang Zhiwei
- 创建于: 2023-05-03 18:45:46
- 更新于: 2023-09-02 23:05:06
- 链接: https://huangzhw0221.github.io/2023/05/03/Learning-测试方法基础/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。